PostgreSQL 10/11
New Features
Brought to you by Alexey Vasiliev, Railsware

Alexey Vasiliev, Railsware
Brought to you by Alexey Vasiliev, Railsware
![]() PostgreSQL ("Postgres") - is an object-relational database management system (ORDBMS) with an emphasis on extensibility and standards-compliance. Based on the SQL language and supports many of the features of the standard SQL:2011. PostgreSQL evolved from the Ingres project at the University of California, Berkeley. In 1982 the leader of the Ingres team, Michael Stonebraker, left Berkeley to make a proprietary version of Ingres. He returned to Berkeley in 1985 and started a post-Ingres project
PostgreSQL ("Postgres") - is an object-relational database management system (ORDBMS) with an emphasis on extensibility and standards-compliance. Based on the SQL language and supports many of the features of the standard SQL:2011. PostgreSQL evolved from the Ingres project at the University of California, Berkeley. In 1982 the leader of the Ingres team, Michael Stonebraker, left Berkeley to make a proprietary version of Ingres. He returned to Berkeley in 1985 and started a post-Ingres project
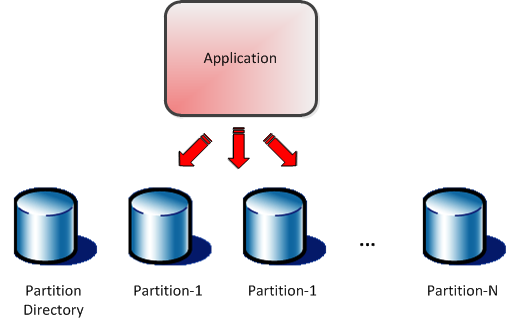
CREATE TABLE numbers (x INTEGER) PARTITION BY RANGE (x);
CREATE TABLE negatives PARTITION OF numbers FOR
VALUES FROM (MINVALUE) TO (0);
CREATE TABLE positives PARTITION OF numbers FOR
VALUES FROM (0) TO (MAXVALUE);# INSERT INTO numbers VALUES (-3), (-1), (9), (99);
INSERT 0 4
# SELECT * FROM numbers;
x
----
-3
-1
9
99
(4 rows)# SELECT * FROM negatives;
x
----
-3
-1
(2 rows)
# SELECT * FROM positives;
x
----
9
99
(2 rows)# SELECT * FROM ONLY numbers;
x
---
(0 rows)# CREATE TABLE book_history_2016_07
PARTITION OF book_history
FOR VALUES FROM ('2016-07-01 00:00:00')
TO ('2016-09-01 00:00:00');
ERROR: partition "book_history_2016_07" would
overlap partition "book_history_2016_08"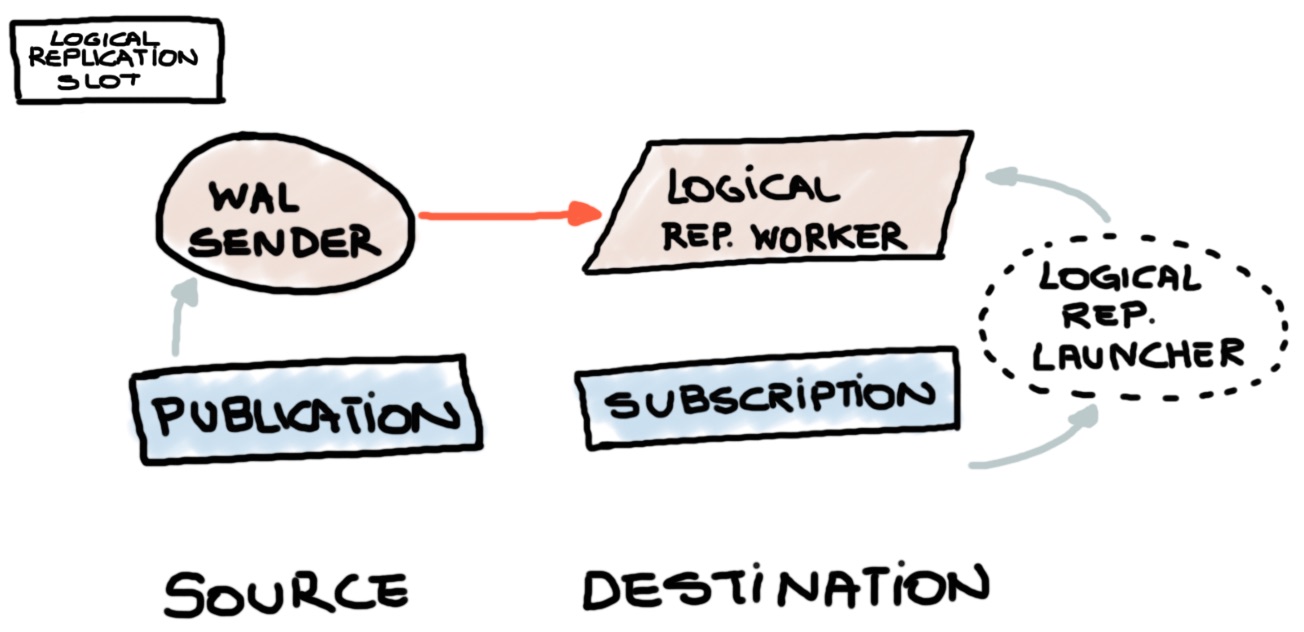
# CREATE PUBLICATION financials FOR TABLE
ONLY loans, ONLY fines;
origin# pg_dump libdata -Fc -f /netshare/libdata.dump
replica# pg_restore -d
libdata -s -t loans -t fines /netshare/libdata.dump
# CREATE SUBSCRIPTION financials
CONNECTION 'dbname=libdata user=postgres host=172.17.0.2'
PUBLICATION financials;
NOTICE: synchronized table states
NOTICE: created replication slot "financials" on publisher
CREATE SUBSCRIPTION # SELECT * FROM pg_stat_subscription;
-[ RECORD 1 ]---------+---------------------
subid | 16475
subname | financials
pid | 167
relid |
received_lsn | 0/1FBEAF0
last_msg_send_time | 2017-06-07 00:59:44
last_msg_receipt_time | 2017-06-07 00:59:44
latest_end_lsn | 0/1FBEAF0
latest_end_time | 2017-06-07 00:59:44# \timing
Timing is on.
# SELECT bid, count(*) FROM account_history
WHERE delta > 1000 group by bid;
...
Time: 324.903 ms# set max_parallel_workers_per_gather=4;
SET
Time: 0.822 ms
# SELECT bid, count(*) FROM account_history
WHERE delta > 1000 GROUP BY bid;
...
Time: 72.864 ms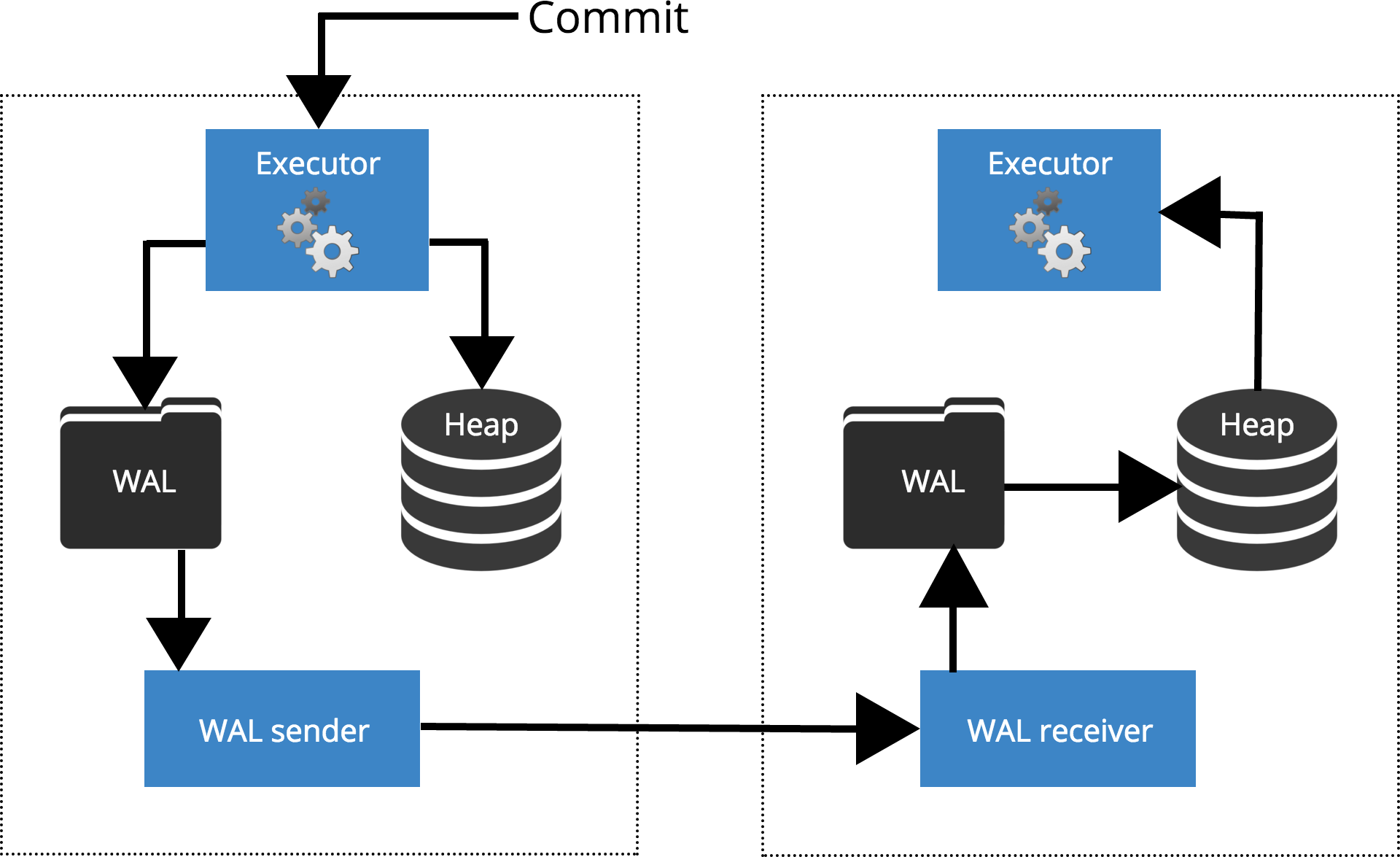
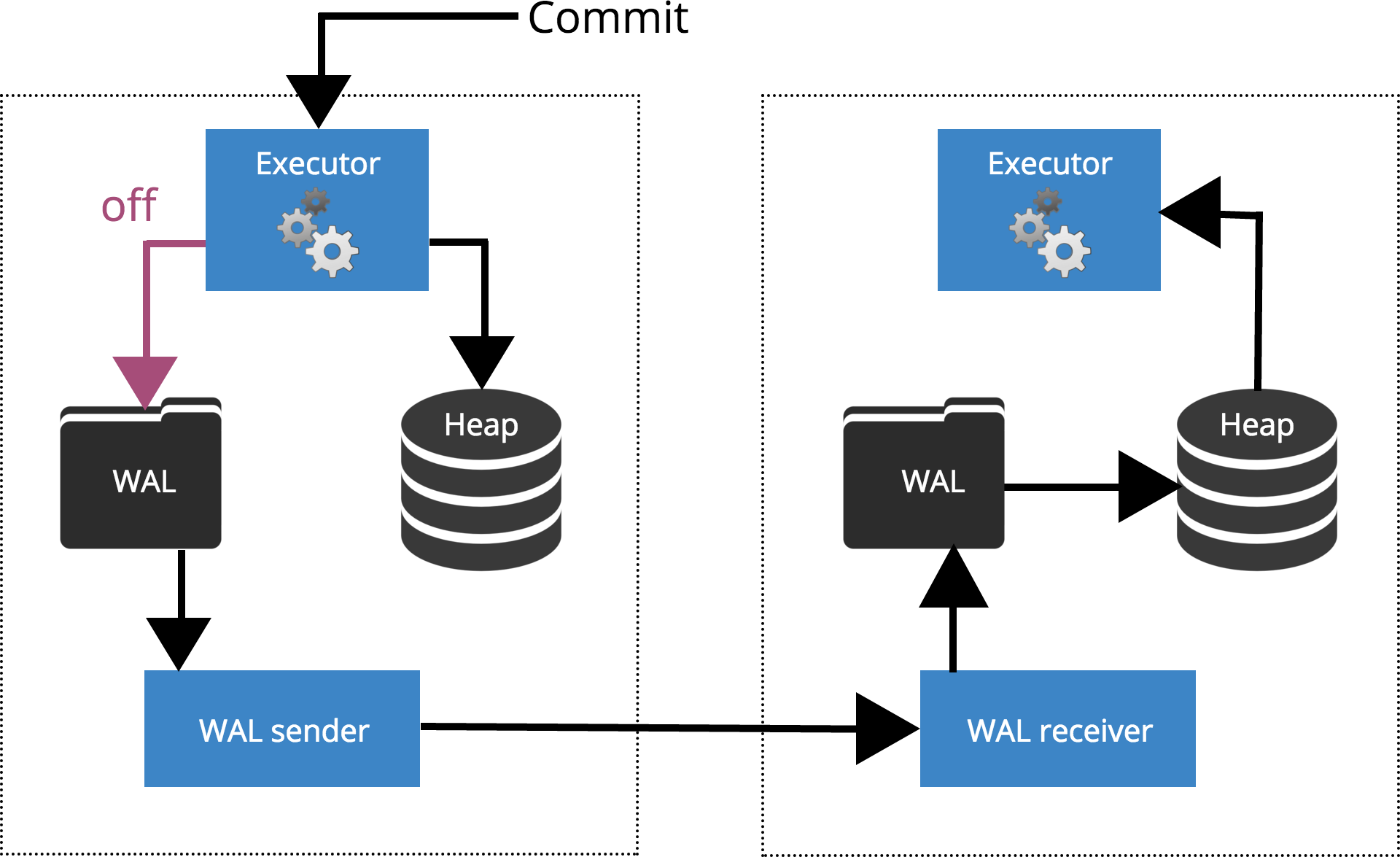
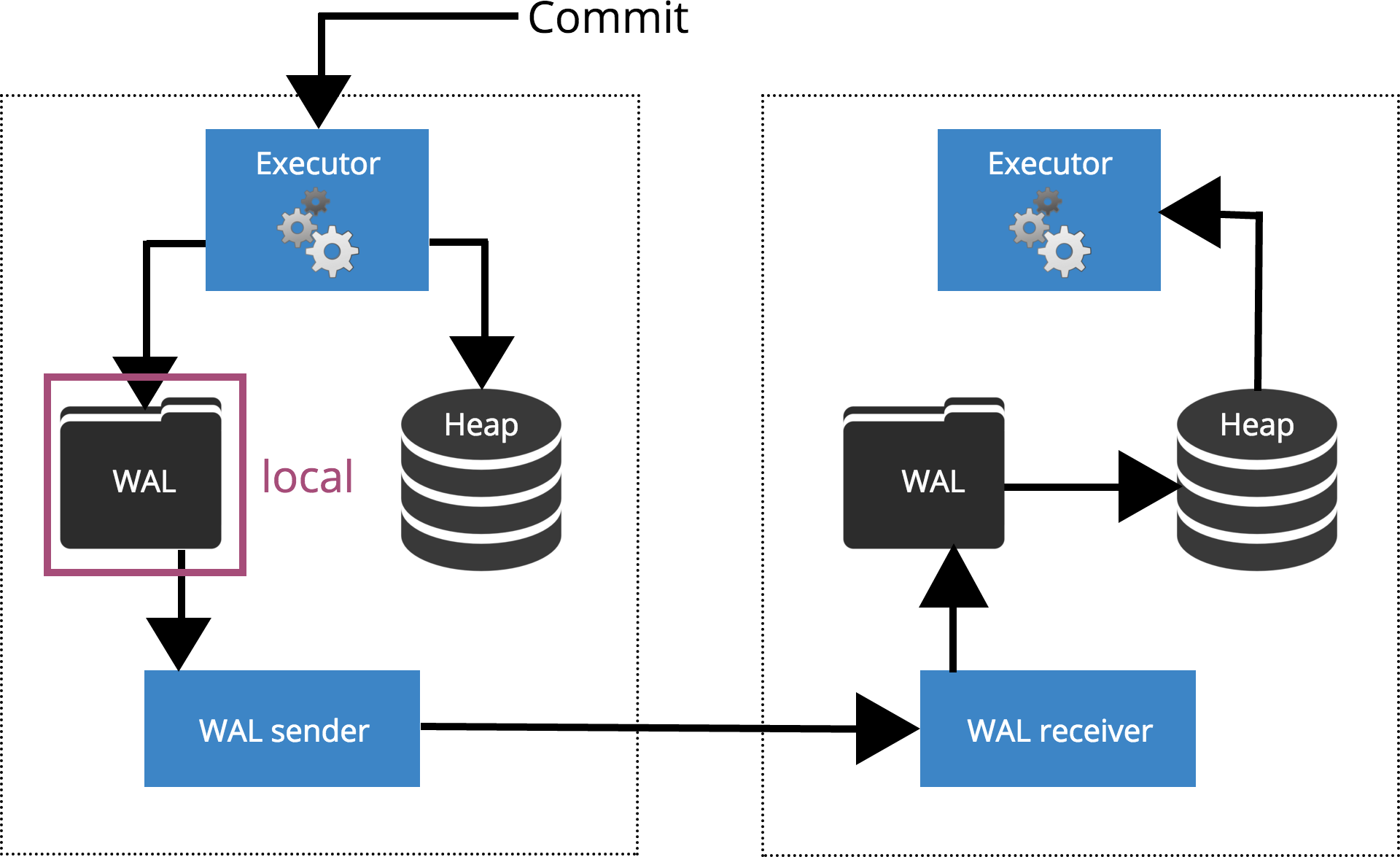
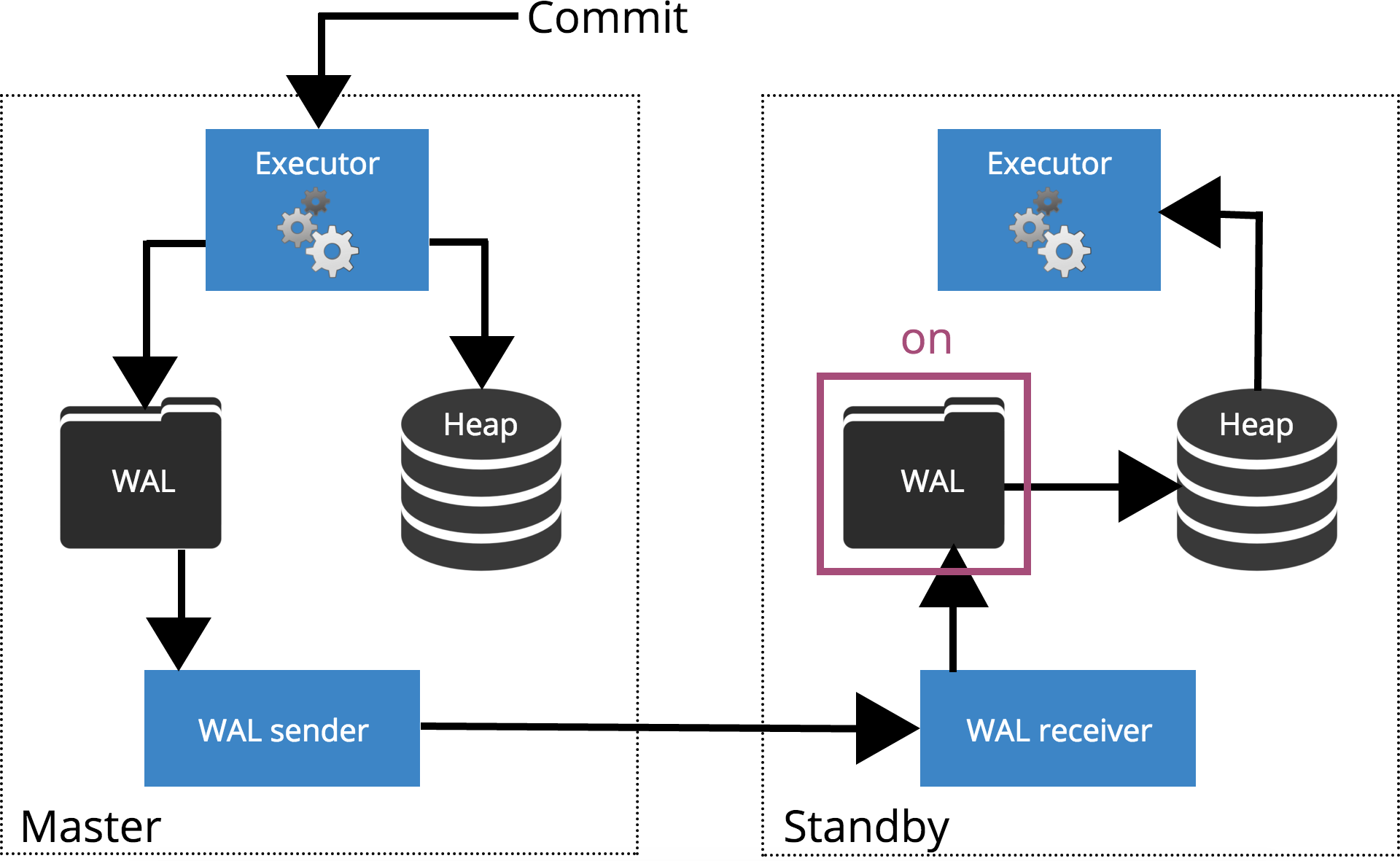
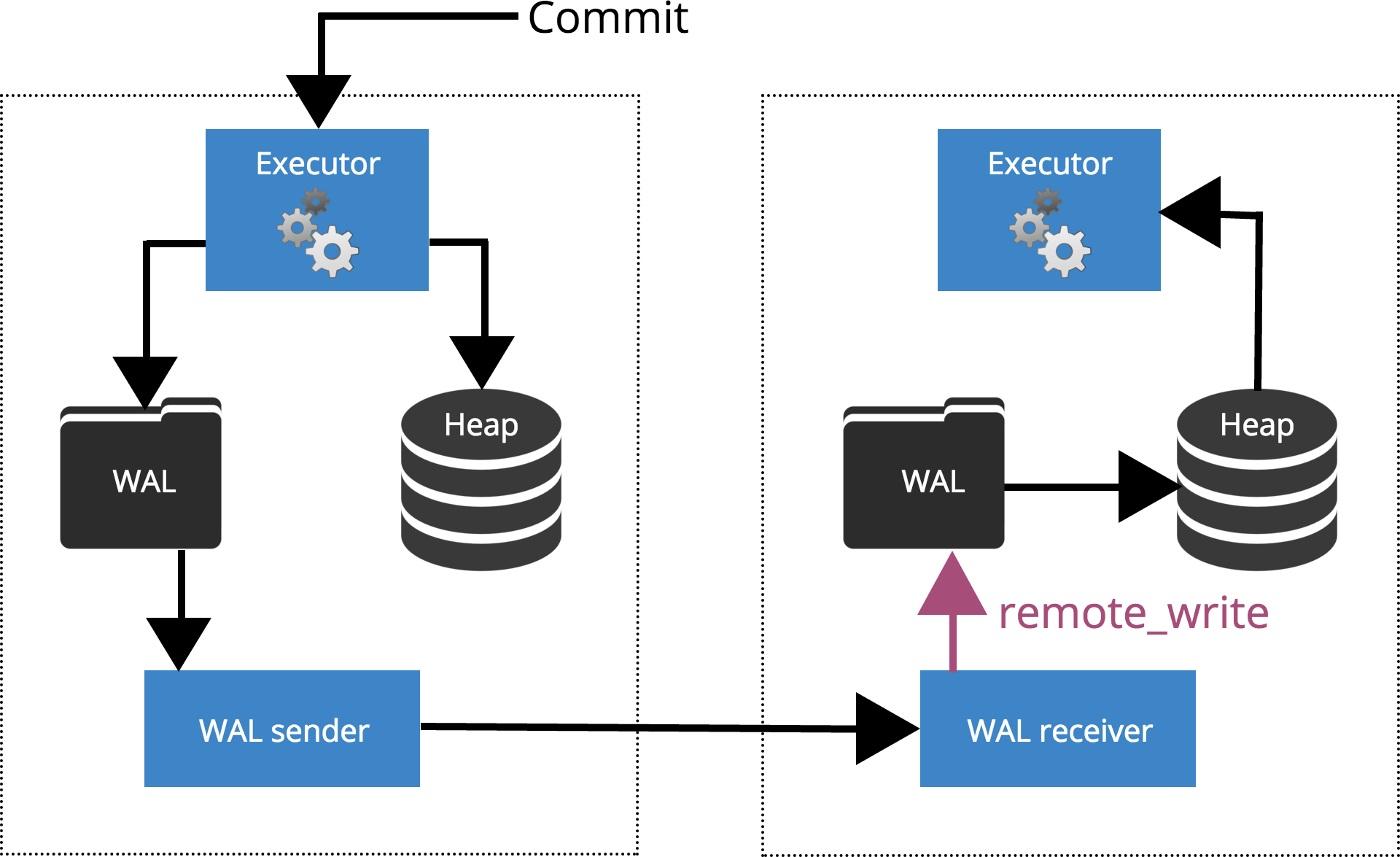
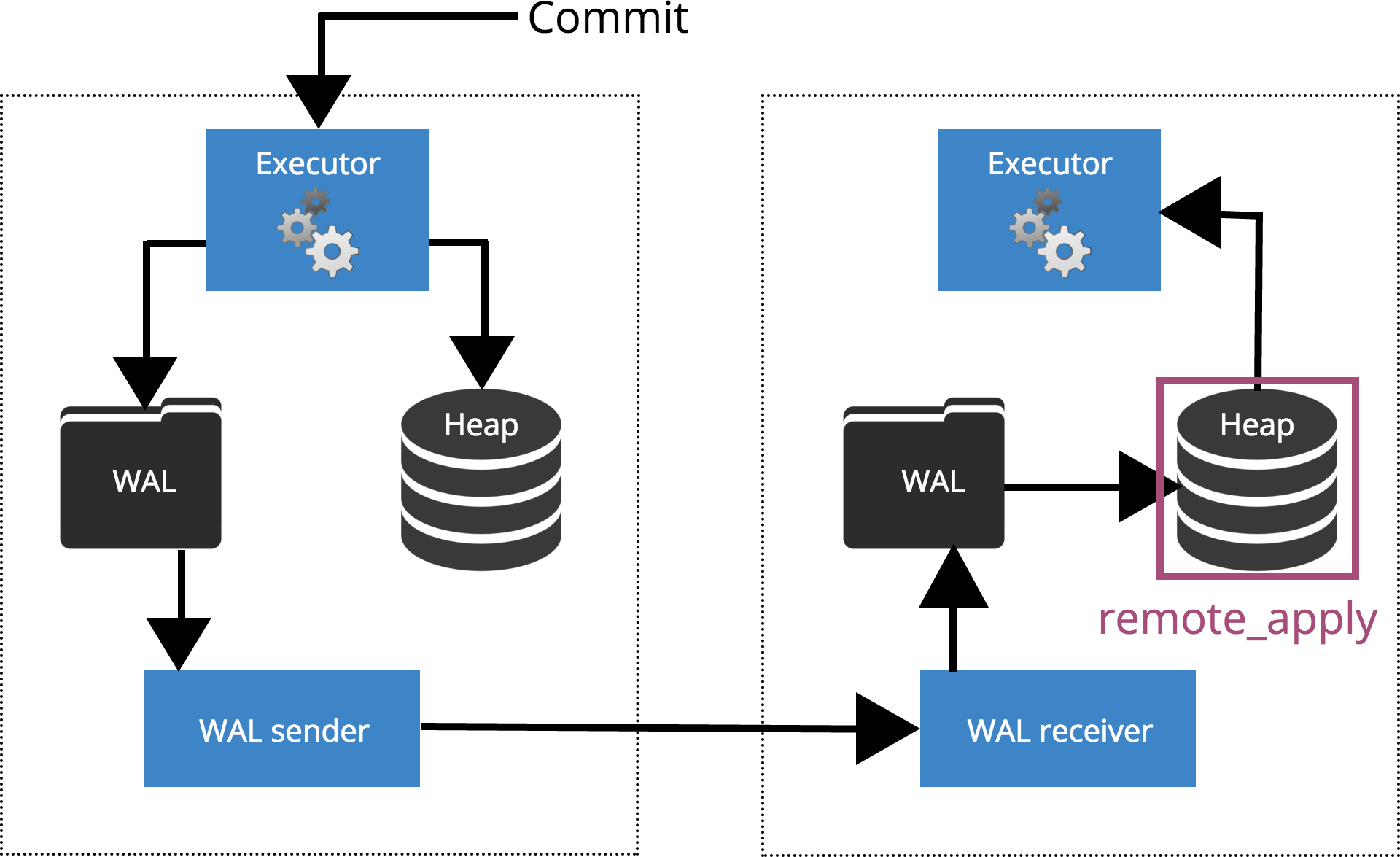
synchronous_standby_names = FIRST 2(node1,node2,node3);
synchronous_standby_names = ANY 2(node1,node2,node3);
$ explain (analyze on, verbose on) select group_id,
count(*) from data_from_origin group by group_id order by group_id;
QUERY PLAN
--------------------------------------------------------------------------------------
GroupAggregate (cost=100.00..222.22 rows=200 width=12) (actual time=55.823..119.840 rows=11 loops=1)
Output: group_id, count(*)
Group Key: data_from_origin.group_id
-> Foreign Scan on public.data_from_origin (cost=100.00..205.60 rows=2925 width=4)
(actual time=51.703..110.939 rows=100000 loops=1)
Output: id, group_id
Remote SQL: SELECT group_id FROM public.sample_data ORDER BY group_id ASC NULLS LAST
Execution time: 120.534 ms
(8 rows)$ explain (analyze on, verbose on) select group_id, count(*)
from data_from_origin group by group_id order by group_id;
QUERY PLAN
----------------------------------------------------------------------------------------------------------
Sort (cost=167.52..168.02 rows=200 width=12) (actual time=21.606..21.607 rows=11 loops=1)
Output: group_id, (count(*))
Sort Key: data_from_origin.group_id
Sort Method: quicksort Memory: 25kB
-> Foreign Scan (cost=114.62..159.88 rows=200 width=12)
(actual time=21.596..21.597 rows=11 loops=1)
Output: group_id, (count(*))
Relations: Aggregate on (public.data_from_origin)
Remote SQL: SELECT group_id, count(*) FROM public.sample_data GROUP BY group_id
Execution time: 21.900 ms
(10 rows)$ create user test;
CREATE USER
$ alter user test with password 'abba1234';
ALTER USER
$ select usename, passwd from pg_shadow where usename = 'test';
usename | passwd
---------+-------------------------------------
test | md5b9ad53e3f2f85cd793091f661832fd34
(1 row)To enable scram passwords, we will need to change, in postgresql.conf:
password_encryption = scram-sha-256$ create user test2 with password 'abba1234';
CREATE ROLE
$ create user test3 with password 'abba1234';
CREATE ROLE
$ select usename, passwd from pg_shadow where usename ~ '^test[23]$';
usename | passwd
---------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------
test2 | scram-sha-256:jEpSN6AcvbKsRw==:4096:ff2ccc8e61b4b638b28dfb1c99e44df1a63a2c6a53424a6f4c2e448caeaa46cd:86ef4490e67117fca17e3cc7f7b8276ea8777a656cfb2e41e82037e4e98d128b
test3 | scram-sha-256:A1x/O56i589Puw==:4096:de83debb226eebda74a16ddf66f9c878115f3d4d73653bf863f3e8e9e95d95ff:ba05283f9a3620fa290c5ec916e8729d9e7c0f89f728b1eb0a6850f522a0eebc
(2 rows)$ drop user test2;
DROP ROLE
$ create user test2 with password 'abba1234';
CREATE ROLE
$ select usename, passwd from pg_shadow where usename = 'test2';
usename | passwd
---------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------
test2 | scram-sha-256:vKJJkdipOsrasw==:4096:6648b76ebb17fa4e13b1900e62829d2a87ddede160954a7bc596cb688034b2b6:fa1321166eb3259fc8ae0ed73ed5725adb2b170ff784b3047d9318b466d3555b
(1 row)SCRAM-SHA-256 provides a more secure password authentication method than MD5:
$ CREATE TABLE hoteldata AS SELECT xml
$$<hotels>
<hotel id="mancha">
<name>La Mancha</name>
<rooms>
<room id="201"><capacity>3</capacity><comment>Great view of the Channel</comment></room>
<room id="202"><capacity>5</capacity></room>
</rooms>
<personnel>
<person id="1025">
<name>Ferdinando Quijana</name><salary currency="PTA">45000</salary>
</person>
</personnel>
</hotel>
...
</hotels>$$ AS hotels;$ SELECT xmltable.*
FROM hoteldata,
XMLTABLE ('/hotels/hotel/rooms/room' PASSING hotels
COLUMNS
id FOR ORDINALITY,
hotel_name text PATH '../../name' NOT NULL,
room_id int PATH '@id' NOT NULL,
capacity int,
comment text PATH 'comment' DEFAULT 'A regular room'
); id | hotel_name | room_id | capacity | comment
----+------------+---------+----------+---------------------------
1 | La Mancha | 201 | 3 | Great view of the Channel
2 | La Mancha | 202 | 5 | A regular room
3 | Valparaíso | 201 | 2 | Very noisy
4 | Valparaíso | 202 | 2 | A regular room
(4 rows)# CREATE INDEX bookdata_fts ON bookdata
USING gin (( to_tsvector('english',bookdata) ));
CREATE INDEX# SELECT bookdata -> 'title'
FROM bookdata
WHERE to_tsvector('english',bookdata) @@ to_tsquery('duke');
------------------------------------------
"The Tattooed Duke"
"She Tempts the Duke"
"The Duke Is Mine"
"What I Did For a Duke"# CREATE TABLE t (a INT, b INT);
# INSERT INTO t SELECT i % 100, i % 100 FROM
generate_series(1, 10000) s(i);
# ANALYZE t;# SELECT relpages, reltuples FROM pg_class WHERE relname = 't';
relpages | reltuples
----------+-----------
45 | 10000
(1 row)# EXPLAIN (ANALYZE, TIMING OFF) SELECT * FROM t WHERE a = 1;
QUERY PLAN
-------------------------------------------------------------------------------
Seq Scan on t (cost=0.00..170.00 rows=100 width=8)
(actual rows=100 loops=1)
Filter: (a = 1)
Rows Removed by Filter: 9900
Planning time: 0.222 ms
Execution time: 2.020 ms
(5 rows)# EXPLAIN (ANALYZE, TIMING OFF) SELECT * FROM t
WHERE a = 1 AND b = 1;
QUERY PLAN
-----------------------------------------------------------------------------
Seq Scan on t (cost=0.00..195.00 rows=1 width=8)
(actual rows=100 loops=1)
Filter: ((a = 1) AND (b = 1))
Rows Removed by Filter: 9900
Planning time: 0.130 ms
Execution time: 1.961 ms
(5 rows)# CREATE STATISTICS stts (dependencies) ON a, b FROM t;
CREATE STATISTICS
# ANALYZE t;
ANALYZE# EXPLAIN (ANALYZE, TIMING OFF) SELECT * FROM t
WHERE a = 1 AND b = 1;
QUERY PLAN
-------------------------------------------------------------------------------
Seq Scan on t (cost=0.00..195.00 rows=100 width=8)
(actual rows=100 loops=1)
Filter: ((a = 1) AND (b = 1))
Rows Removed by Filter: 9900
Planning time: 0.248 ms
Execution time: 1.969 ms
(5 rows)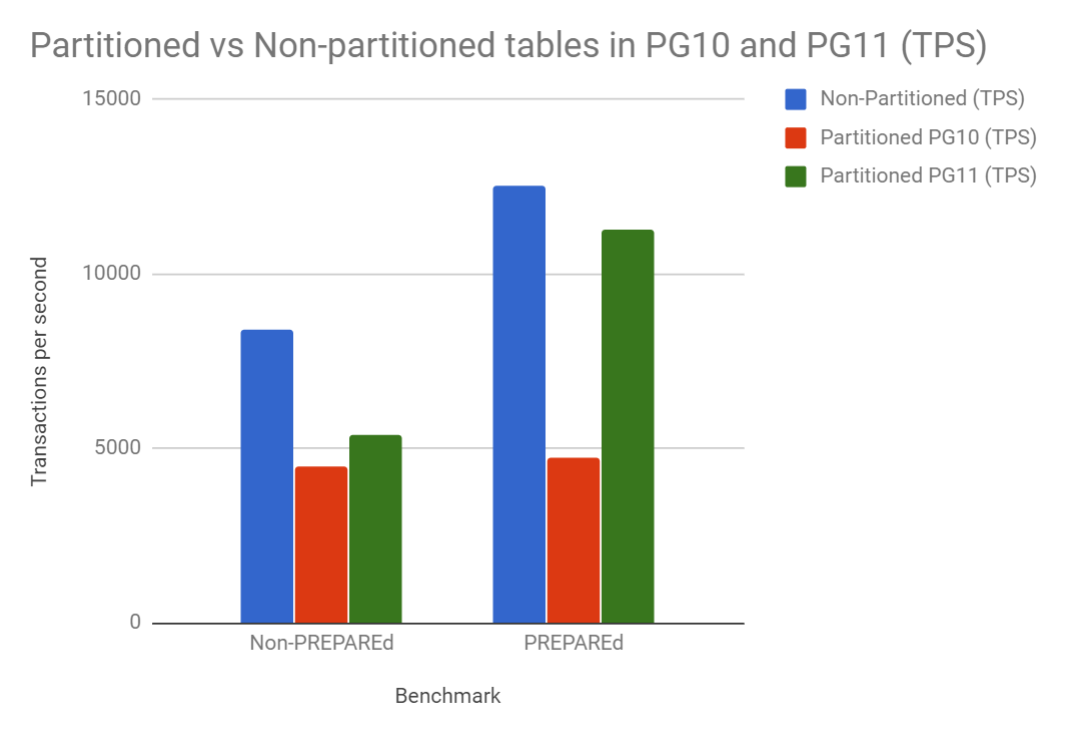
=# CREATE TABLE test (k serial primary key,
v text, ts timestamp);
CREATE TABLE
=# INSERT INTO test (v, ts)
select 'key_' || s , now()
FROM generate_series(1, 10000) as s;
INSERT 0 10000
=# CREATE INDEX ON test (v);
CREATE INDEX=# EXPLAIN SELECT v, ts FROM test WHERE v > 'key_1337' and v < 'key_2337';
QUERY PLAN
-----------------------------------------------------------------------------
Bitmap Heap Scan on test (cost=31.57..112.09 rows=1101 width=16)
Recheck Cond: ((v > 'key_1337'::text) AND (v < 'key_2337'::text))
-> Bitmap Index Scan on test_v_idx (cost=0.00..31.29 rows=1101 width=0)
Index Cond: ((v > 'key_1337'::text) AND (v < 'key_2337'::text))
(4 rows)=# DROP INDEX test_v_idx;
=# CREATE INDEX ON test (v) INCLUDE (ts);
=# EXPLAIN select v, ts from test WHERE v > 'key_1337' and v < 'key_2337';
Index Only Scan using test_v_ts_idx on test
(cost=0.29..46.30 rows=1101 width=16)
Index Cond: ((v > 'key_1337'::text) AND (v < 'key_2337'::text))
(2 rows)=# CREATE OR REPLACE FUNCTION testit(jsonb) RETURNS void as $$
my $arg = shift;
elog(NOTICE, "Arg is: [$arg]");
elog(NOTICE, "Arg ref is: [" . ref($arg) . "]");
elog(NOTICE, "Arg len is: [" . length($arg) . "]");
$$ language plperl;
=# SELECT testit( '{ "id": 1, "name": "A green door",
"price": 12.50, "tags": ["home", "green"] }'::jsonb );=# CREATE OR REPLACE FUNCTION testit(jsonb)
RETURNS void
TRANSFORM FOR TYPE jsonb
LANGUAGE plperl
as $$
my $arg = shift;
elog(NOTICE, "Arg is: [$arg]");
elog(NOTICE, "Arg ref is: [" . ref($arg) . "]");
elog(NOTICE, "Arg len is: [" . length($arg) . "]");
$$;
=# SELECT testit( '{ "id": 1, "name": "A green door",
"price": 12.50, "tags": ["home", "green"] }'::jsonb );