Machine
Learning
in Ruby
Brought to you by Alexey Vasiliev, Railsware

Alexey Vasiliev, Railsware
Brought to you by Alexey Vasiliev, Railsware

If you and/or your organization don’t have good, clean data, you are most definitely not ready for machine learning. Data management should be your first step before diving into any other data project(s)

Classifier Reborn is a general classifier module to allow Bayesian Classifier and Latent Semantic Indexer (LSI)
gem install classifier-reborn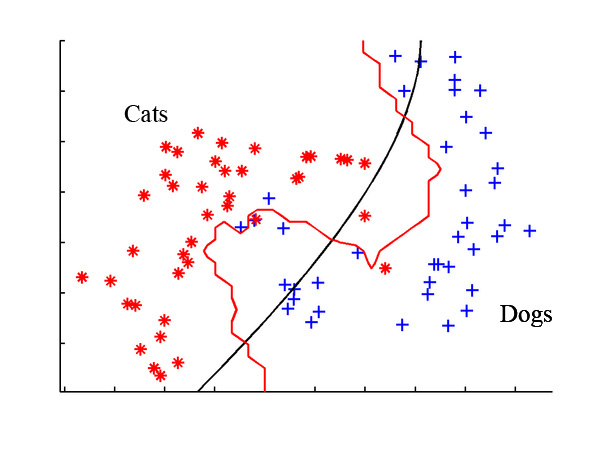
Decision Tree a ruby library which implements ID3 (information gain) algorithm for decision tree learning
gem install decisiontree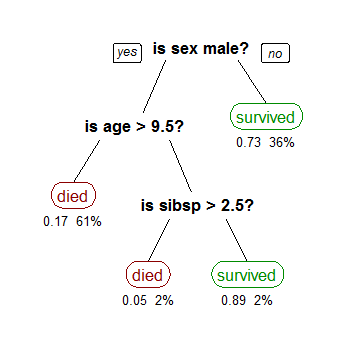
K Nearest Neighbours (KNN) a simple algorithm that stores all available cases and classifies new cases based on a similarity measure (e.g., distance functions)
gem install knn
Similarity a Ruby library for calculating the similarity between pieces of text using a Term Frequency-Inverse Document Frequency (TF-IDF) method
gem install similarity




OpenCV (Open Source Computer Vision Library) is an open source computer vision and machine learning software library
Gems: Ruby-opencv

Apache Mahout project's goal is to build an environment for quickly creating scalable performant machine learning applications
Gems: JRuby Mahout

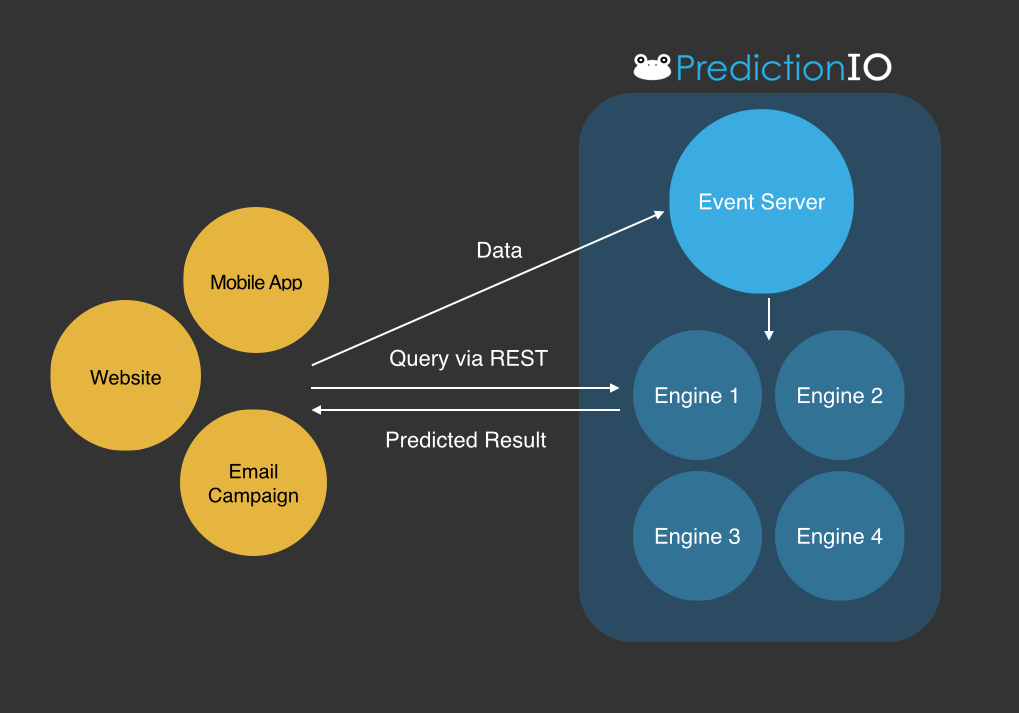
Apache PredictionIO (incubating) is an open source Machine Learning Server built on top of state-of-the-art open source stack for developers and data scientists create predictive engines for any machine learning task

TensorFlow is an open source software library for numerical computation using data flow graphs
Gems: Tensorflow.rb



