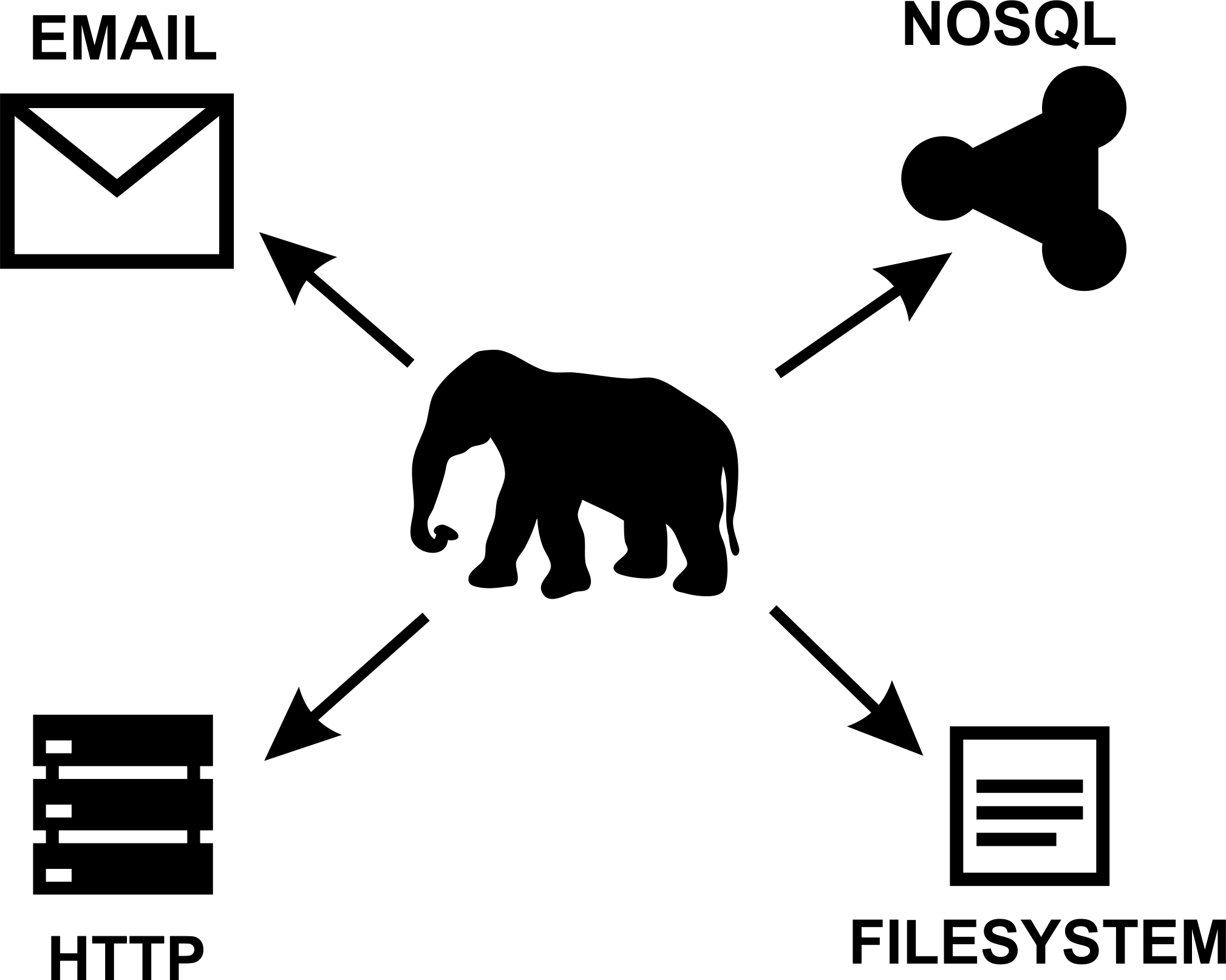
Alexey Vasiliev, Railsware



That which doesn't fit in an Excel spreadsheet.
Any data too big for copy to DVDs and fit into 1 Lada.
When person monitors database, it is called small data and when database monitors person, it is called big data.
Big data is like teenage sex: everyone talks about it, nobody really knows how to do it, everyone thinks everyone else is doing it, so everyone claims they are doing it.

![]() PostgreSQL ("Postgres") - is an object-relational database management system (ORDBMS) with an emphasis on extensibility and standards-compliance. Based on the SQL language and supports many of the features of the standard SQL:2011. PostgreSQL evolved from the Ingres project at the University of California, Berkeley. In 1982 the leader of the Ingres team, Michael Stonebraker, left Berkeley to make a proprietary version of Ingres. He returned to Berkeley in 1985 and started a post-Ingres project
PostgreSQL ("Postgres") - is an object-relational database management system (ORDBMS) with an emphasis on extensibility and standards-compliance. Based on the SQL language and supports many of the features of the standard SQL:2011. PostgreSQL evolved from the Ingres project at the University of California, Berkeley. In 1982 the leader of the Ingres team, Michael Stonebraker, left Berkeley to make a proprietary version of Ingres. He returned to Berkeley in 1985 and started a post-Ingres project

| Limit | Value |
|---|---|
| Maximum Database Size | Unlimited |
| Maximum Table Size | 32 TB |
| Maximum Row Size | 1.6 TB |
| Maximum Field Size | 1 GB |
| Maximum Rows per Table | Unlimited |
| Maximum Columns per Table | 250-1600 depending on column types |
| Maximum Indexes per Table | Unlimited |
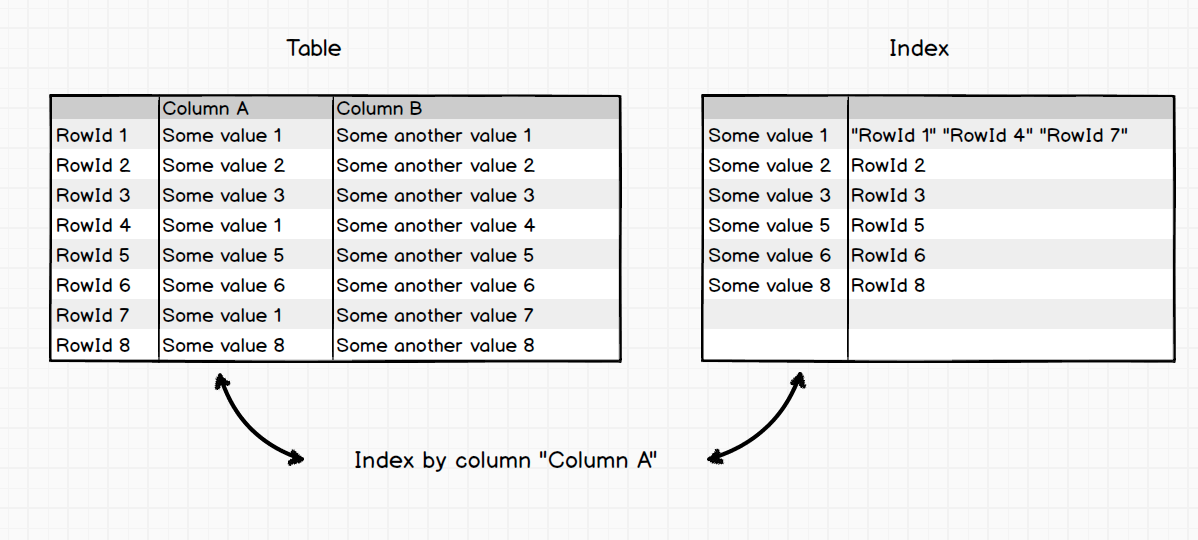
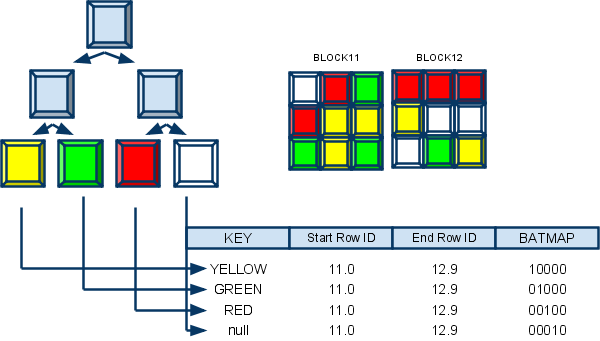

# \dt+ orders
List of relations
Schema | Name | Type | Owner | Size | Description
--------+--------+-------+-------+-------+-------------
public | orders | table | leo | 13 GB |
(1 row)# EXPLAIN ANALYSE SELECT count(*) FROM orders
WHERE order_date BETWEEN '2012-01-04 09:00:00'
and '2014-01-04 14:30:00';
...
Planning time: 0.140 ms
Execution time: 30172.482 ms
(6 rows)# CREATE INDEX idx_order_date_brin ON orders
USING BRIN (order_date);
# \di+ idx_order_date_brin
List of relations
Schema | Name | Type | Owner | Table | Size | Description
--------+---------------------+-------+-------+--------+--------+-------------
public | idx_order_date_brin | index | leo | orders | 504 kB |
(1 row)# EXPLAIN ANALYSE SELECT count(*) FROM orders
WHERE order_date BETWEEN '2012-01-04 09:00:00'
and '2014-01-04 14:30:00';
...
-> Bitmap Index Scan on idx_order_date_brin
Index Cond: ((order_date >= '2012-01-04 09:00:00+00'::timestamp with time zone) AND (order_date <= '2014-01-04 14:30:00+00'::timestamp with time zone))
Planning time: 0.108 ms
Execution time: 6347.701 ms
(9 rows)# CREATE INDEX idx_order_date_brin_32
ON orders
USING BRIN (order_date) WITH (pages_per_range = 32);
# CREATE INDEX idx_order_date_brin_512
ON orders
USING BRIN (order_date) WITH (pages_per_range = 512);# \di+ idx_order_date_brin*
List of relations
Schema | Name | Table | Size
--------+-------------------------+--------+---------
public | idx_order_date_brin | orders | 504 kB
public | idx_order_date_brin_32 | orders | 1872 kB
public | idx_order_date_brin_512 | orders | 152 kB
(3 rows)The only difference between json and jsonb is their storage:
There are 3 major consequences of this:
# SELECT '{"name": "Joe", "age": 30}'::jsonb
|| '{"town": "London"}'::jsonb;
?column?
----------------------------------------------
{"age": 30, "name": "Joe", "town": "London"}| Operator | Description |
|---|---|
| -> | Get an element by key as a JSON object |
| ->> | Get an element by key as a text object |
| #> | Get an element by path as a JSON object |
| #>> | Get an element by path as a text object |
| <@, @> | Evaluate whether a JSON object contains a key/value pair |
| ? | Evaluate whether a JSON object contains a key or a value |
| ?| | Evaluate whether a JSON object contains ANY of keys or values |
| ?& | Evaluate whether a JSON object contains ALL of keys or values |
| || | Insert or Update an element to a JSON object |
| - | Delete an element by key from a JSON object |
| #- | Delete an element by path from a JSON object |
# WITH prepared_data AS ( ... )
SELECT data, count(data),
min(data), max(data)
FROM prepared_data
GROUP BY data;# WITH RECURSIVE t(n) AS (VALUES (1)
UNION ALL SELECT n+1 FROM t WHERE n < 100)
SELECT sum(n) FROM t;
sum
------
5050
(1 row)# SELECT depname, empno, salary, avg(salary) OVER (PARTITION BY depname) FROM empsalary;
depname | empno | salary | avg
-----------+-------+--------+-----------------------
develop | 11 | 5200 | 5020.0000000000000000
develop | 7 | 4200 | 5020.0000000000000000
develop | 9 | 4500 | 5020.0000000000000000
develop | 8 | 6000 | 5020.0000000000000000
develop | 10 | 5200 | 5020.0000000000000000
personnel | 5 | 3500 | 3700.0000000000000000
personnel | 2 | 3900 | 3700.0000000000000000
sales | 3 | 4800 | 4866.6666666666666667
sales | 1 | 5000 | 4866.6666666666666667
sales | 4 | 4800 | 4866.6666666666666667
(10 rows)# SELECT salary, sum(salary) OVER (ORDER BY salary) FROM empsalary;
salary | sum
--------+-------
3500 | 3500
3900 | 7400
4200 | 11600
4500 | 16100
4800 | 25700
4800 | 25700
5000 | 30700
5200 | 41100
5200 | 41100
6000 | 47100
(10 rows)# SELECT
COUNT(*) AS unfiltered,
SUM( CASE WHEN i < 5 THEN 1 ELSE 0 END ) AS filtered
FROM generate_series(1,10) AS s(i);
# SELECT
COUNT(*) AS unfiltered,
COUNT(*) FILTER (WHERE i < 5) AS filtered
FROM generate_series(1,10) AS s(i);# SELECT mode() WITHIN GROUP (ORDER BY some_value)
AS modal_value FROM tbl;
mode
------
9
(1 row)# SELECT v, RANK() OVER(ORDER BY v) FROM t;
| V | RANK |
|---|------|
| a | 1 |
| a | 1 |
| b | 3 |
| c | 4 |
| c | 4 |
| d | 6 |# SELECT v, DENSE_RANK() OVER(ORDER BY v) FROM t;
| V | DENSE_RANK |
|---|------------|
| a | 1 |
| a | 1 |
| b | 2 |
| c | 3 |
| c | 3 |
| d | 4 |# SELECT * FROM items_sold;
brand | size | sales
-------+------+-------
Foo | L | 10
Foo | M | 20
Bar | M | 15
Bar | L | 5
(4 rows)# SELECT brand, size, sum(sales) FROM items_sold
GROUP BY GROUPING SETS ((brand), (size), ());
brand | size | sum
-------+------+-----
Foo | | 30
Bar | | 20
| L | 15
| M | 35
| | 50# SELECT brand, size, sum(sales) FROM items_sold GROUP BY CUBE (brand, size);
brand | size | sum
-------+------+-----
Bar | L | 5
Bar | M | 15
Bar | | 20
Foo | L | 10
Foo | M | 20
Foo | | 30
| | 50
| L | 15
| M | 35# CUBE(c1, c2, c3)
(с1, null, null)
(null, c2, null)
(null, null, c3)
(c1, c2, null)
(c1, null, c3)
(null, c2, c3)
(c1, c2, c3)
(null, null, null)# SELECT brand, size, sum(sales) FROM items_sold
GROUP BY ROLLUP (brand, size);
brand | size | sum
-------+------+-----
Bar | L | 5
Bar | M | 15
Bar | | 20
Foo | L | 10
Foo | M | 20
Foo | | 30
| | 50# ROLLUP(c1, c2, c3, c4)
(c1, c2, c3, c4)
(c1, c2, c3, null)
(c1, c2, null, null)
(c1, null, null, null)
(null, null, null, null)# EXPLAIN ANALYZE SELECT * FROM test TABLESAMPLE SYSTEM ( 0.001 );
QUERY PLAN
------------------------------------------------------------------
Sample Scan (system) on test (cost=0.00..0.10 rows=10 width=25)
(actual time=0.029..0.042 rows=136 loops=1)
Planning time: 0.125 ms
Execution time: 0.061 ms
(3 rows)# EXPLAIN ANALYZE SELECT * FROM test TABLESAMPLE BERNOULLI ( 0.001 );
QUERY PLAN
------------------------------------------------------------------
Sample Scan (bernoulli) on test (cost=0.00..7353.10 rows=10 width=25)
(actual time=2.779..27.288 rows=15 loops=1)
Planning time: 0.112 ms
Execution time: 27.312 ms
(3 rows)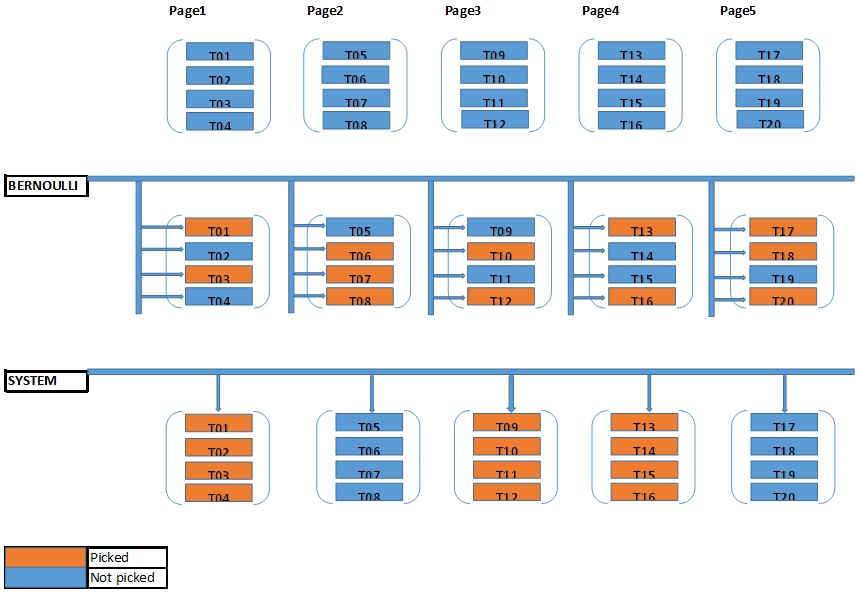
The optional REPEATABLE clause specifies a seed number or expression to use for generating random numbers within the sampling method. The seed value can be any non-null floating-point value. Two queries that specify the same seed and argument values will select the same sample of the table, if the table has not been changed meanwhile
# SELECT * FROM t TABLESAMPLE SYSTEM (0.001) REPEATABLE (200);# REFRESH MATERIALIZED VIEW CONCURRENTLY my_view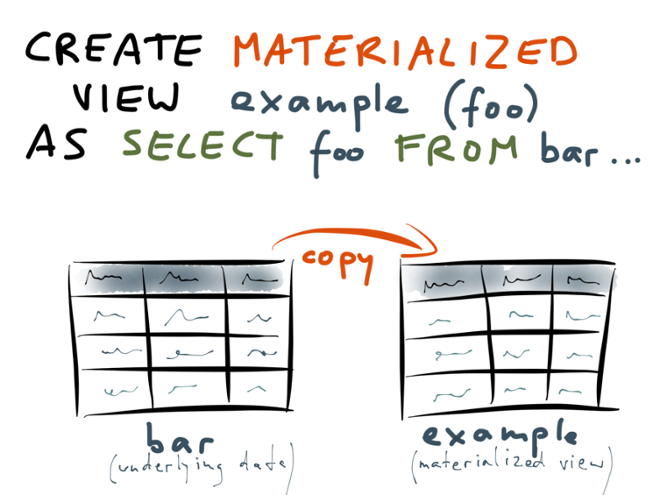
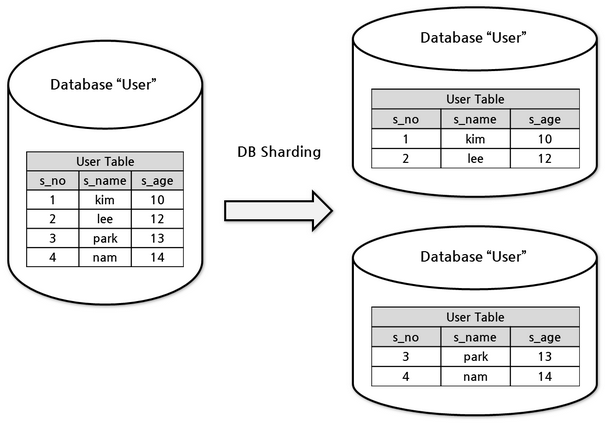
the system is described as an over 2 petabyte repository of user click stream and context data with an update rate for 24 billion events per day
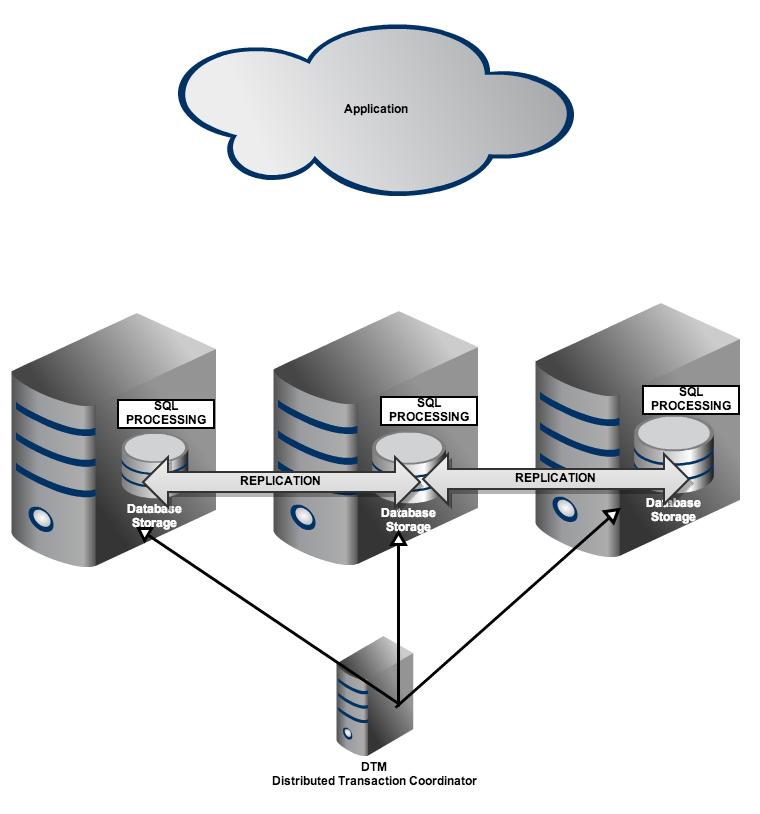
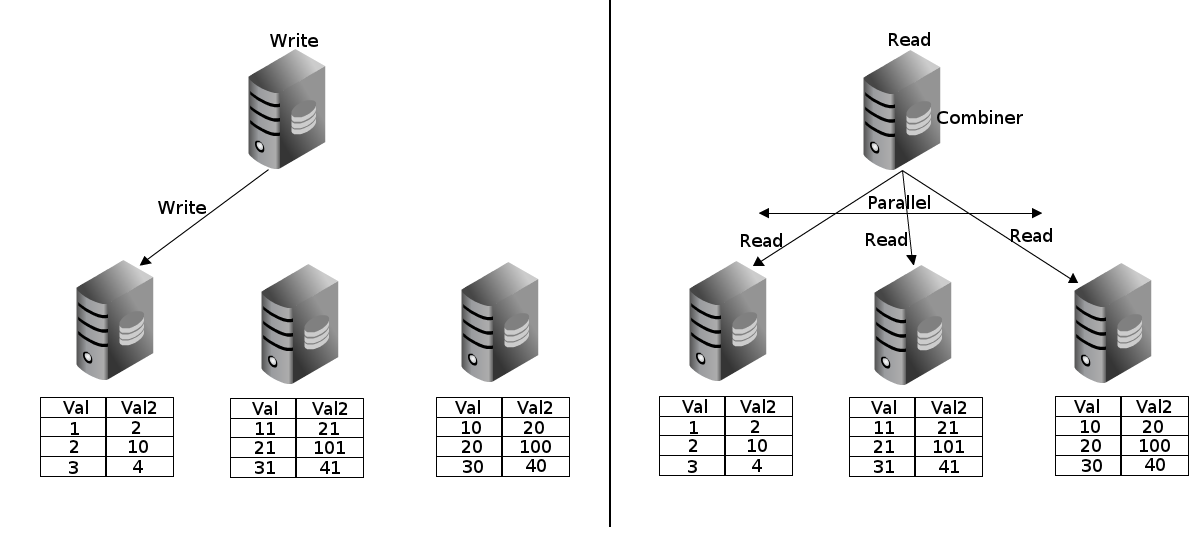
CREATE EXTENSION pg_shard;
CREATE TABLE customer_reviews
(
customer_id TEXT NOT NULL,
review_date DATE,
review_rating INTEGER
);
SELECT master_create_distributed_table('customer_reviews', 'customer_id');
SELECT master_create_worker_shards('customer_reviews', 16, 2);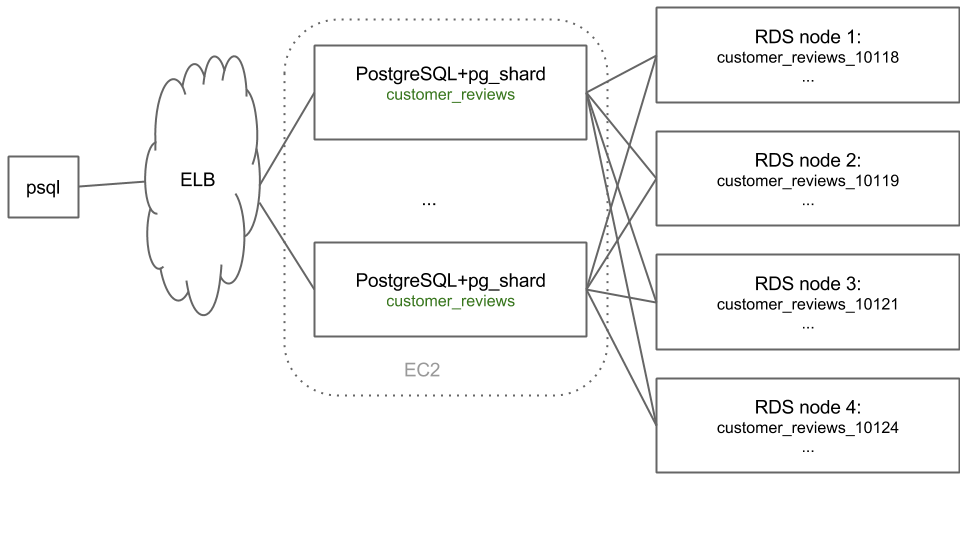
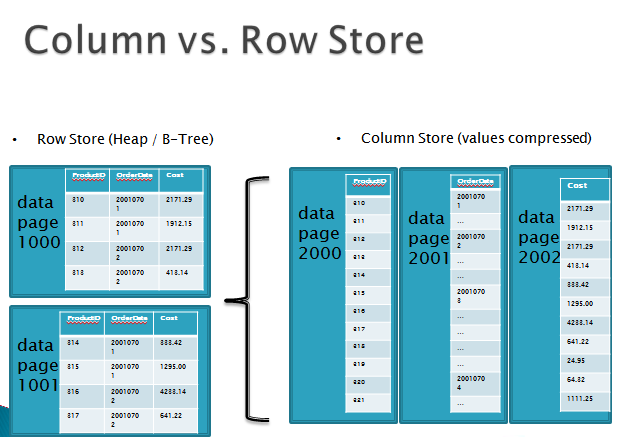

CREATE TABLE events (...);
CREATE TABLE events_current () INHERITS(main);
CREATE FOREIGN TABLE events_201501 (
CHECK(20150101 <= event_date AND event_date <= 20150131)
)
INHERITS(main) SERVER cstore_server OPTIONS(compression 'pglz');